本文用于统一整理JavaSE中的集合框架常见八股问题,会随着面试内容进行更新
1.常用的集合框架有哪些
此处配手画图
队列和栈的区别知道吗?
队列是一种先进先出的数结构,而栈是先进后出的数据结构(数据结构经典题目之栈的最小大小为)
线程安全的容器有哪些知道吗?
Vector、Hashtable、ConcurrentHashMap、CopyOnWriteArrayList、ConcurrentLinkedQueue、ArrayBlockingQueue、LinkedBlockingQueue 都是线程安全的
2.ArrayList 和 LinkedList 有什么区别?
结构上:ArrayList 是基于数组实现的,LinkedList 是基于链表实现的
用途上:ArrayList 更利于查找,LinkedList 更利于增删
查找上:由于 ArrayList 是基于数组实现的,所以 get(int index) 可以直接通过数组下标获取,时间复杂度是 O(1);LinkedList 是基于链表实现的,get(int index) 需要遍历链表,时间复杂度是 O(n)。
当然,get(E element) 这种查找,两种集合都需要遍历通过 equals 比较获取元素,所以时间复杂度都是 O(n)
删除上:ArrayList如果删除的是尾部的数据,复杂度就是O(1),如果删除中间的部分,就会涉及到复制数组,还可能触发扩容,性能消耗较大。LinkedList删除如果是在头部和尾部的话复杂度就是O(1),如果是在中间的话复杂度就是O(n),因为需要遍历找到插入点,但插入只需要指定好前驱和后继即可
随机查找上:ArrayList 是基于数组的,也实现了 RandomAccess 接口,所以它支持随机访问,可以通过下标直接获取元素。LinkedList 是基于链表的,所以它没法根据下标直接获取元素,不支持随机访问。
占用内存上:ArrayList 是基于数组的,是一块连续的内存空间,如果涉及到扩容,就会重新分配内存,空间是原来的 1.5 倍。LinkedList 是基于链表的,不需要连续的内存空间,每个节点都存储着指向下一个节点的指针
使用场景上:ArrayList 适用于读取操作远多于写入操作,如存储不经常改变的列表,需要频繁在列表末尾添加元素的场景。LinkedList 适用于频繁插入和删除,不需要快速随机访问。
3.ArrayList 的扩容机制了解吗?
当ArrayList每次需要添加新数据的时候都会进行扩容检测,如果当前容量+1超过数据长度,将会扩容到原先的1.5倍,并把旧数据中的元素拷贝到新数据中去,这样的过程会有性能损耗。
4.快速失败fail-fast了解吗?
是一种错误检测机制,在我们使用迭代器对集合对象进行遍历的时候,迭代器会维护一个modCount的值,在每次使用hashnext()/next()时都会检查modCount的值是否发生了改变(有一个预期值),如果没有改变就会返回遍历的值,发生了改变就会抛出Concurrent Modification Exception。也就是我们不使用迭代器进行删除时,同时遍历集合时会出现的错误。但如果modCount的值又被修改为预期值的话,就不会抛出异常(类似CAS锁的ABA问题)。
什么是安全失败(fail—safe)呢?
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。基于拷贝内容的优点是避免了 Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的
5.CopyOnWriteArrayList 了解多少?
它是线程安全版本的ArrayList,支持读写分离,在写操作的时候,会复制出一个原先数据的副本,写操作会在副本上通过加锁执行(不然多个线程执行任务的话,会把之前线程修改的内容覆盖掉,典型的数据一致性问题),修改完之后就会把旧数组的引用执行这个更新好的新数组上。而读操作不会加锁,在读写并发的时候,读取的是旧数组中的内容。
6.能说一下 HashMap 的底层数据结构吗?
包浆问题,其涉及数据,链表,红黑树
HashMap通过hash计算来计算底层数组中的桶位置,发送哈希冲突的时候会有以下两种情况,如果键相同(还涉及equals方法,我们在重写equals方法的时候也要重写其hash方法,不如HashMap无法正常使用)就会覆盖掉原先的值,如果不同,根据情况放入红黑树或者链表中。
当HashMap中添加的元素数量大于负载因子*数组现有长度的时候(负载因子默认0.75,数组长度一开始默认为16),就会发生扩容(后面会详细提到),发生扩容的话会重新计算哈希值并且长度为原先的2倍,这是为了方便查找做出的决定。只有当数组长度大于64,且链表长度大于8,链表就会进化成为红黑树。
HashMap的key和其KeyValues都可以是Null值
7.你对红黑树了解多少?
红黑树的根节点必须是黑的,叶子节点必须是黑的,红节点下的一定是黑节点,从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点,每个节点要么是红色,要么是黑色
为什么不用二叉树,平衡二叉树,链表为什么要升级成红黑二叉树
二叉树有概率退化成链表,平衡二叉树维护困难,链表太长的话搜索时间慢,红黑树的查找复杂度是O(Log n)
8.HashMap 的 put 流程知道吗?
哈希寻址 → 处理哈希冲突(链表还是红黑树)→插入/覆盖节点 → 判断是否需要扩容
第一步,通过 hash 方法进一步扰动哈希值,以减少哈希冲突。
第二步,进行第一次的数组扩容;并使用哈希值和数组长度进行取模运算,确定索引位置。如果当前位置为空,直接将键值对插入该位置;否则判断当前位置的第一个节点是否与新节点的 key 相同,如果相同直接覆盖 value,如果不同,说明发生哈希冲突。如果是链表,将新节点添加到链表的尾部;如果链表长度大于等于 8,则将链表转换为红黑树。
每次插入新元素后,检查是否需要扩容,如果当前元素个数大于阈值(capacity * loadFactor),则进行扩容,扩容后的数组大小是原来的 2 倍;并且重新计算每个节点的索引,进行数据重新分布。
只重写元素的 equals 方法没重写 hashCode,put 的时候会发生什么?
如果只重写 equals 方法,没有重写 hashCode 方法,那么会导致 equals 相等的两个对象,hashCode 不相等,这样的话,两个对象会被 put 到数组中不同的位置,导致 get 的时候,无法获取到正确的值。
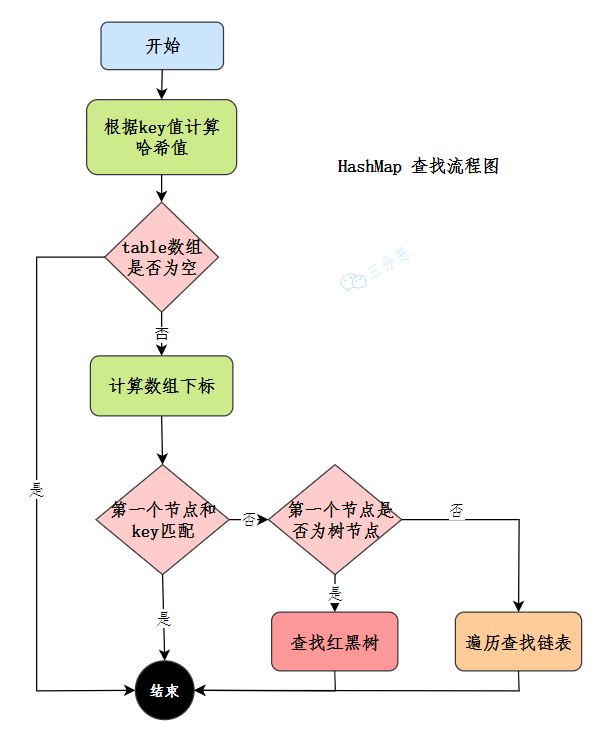
9.HashMap 怎么查找元素的呢?
通过哈希值定位索引 → 定位桶 → 检查第一个节点 → 遍历链表或红黑树查找 → 返回结果。
10.HashMap 的 hash 函数是怎么设计的?为什么 hash 函数能减少哈希冲突?
先拿到 key 的哈希值,是一个 32 位的 int 类型数值,然后再让哈希值的高 16 位和低 16 位进行异或操作,这样能保证哈希分布均匀。哈希表的索引是通过 h & (n-1) 计算的,n 是底层数组的容量;n-1 和某个哈希值做 & 运算,相当于截取了最低的四位。如果数组的容量很小,只取 h 的低位很容易导致哈希冲突。通过异或操作将 h 的高位引入低位,可以增加哈希值的随机性,从而减少哈希冲突。
11.如果初始化 HashMap,传一个 17 的容量,它会怎么处理?
扩容到最接近的最小2的幂次方,也就是32,至于为什么总是2的幂次方,是为了方便计算索引的下标,2的幂次方-1的位运算全是1,可以保证hash值的低位也参与运算,减少冲突概率。并且使用位运算也是比%效率更高
12.解决哈希冲突有哪些方法?
再哈希法、开放地址法和拉链法。HashMap使用的就是拉链法(链表部分)
怎么判断 key 相等呢?
hashCode() :使用key的hashCode()方法计算key的哈希码。
equals() :当两个key的哈希码相同时,HashMap还会调用key的equals()方法进行精确比较。只有当equals()方法返回true时,两个key才被认为是完全相同的。
如果两个key的引用指向了同一个对象,那么它们的hashCode()和equals()方法都会返回true,所以在 equals 判断之前可以先使用==运算符判断一次。
13.HashMap的扩容机制了解吗?
这部分的内容在前面有过叙述了,详细点的地方就是扩容的方法,在JDK8中使用了尾插法,并且当 (e.hash & oldCap) == 0 时,元素保留在原索引的位置;否则元素移动到原索引 + 旧数组大小的位置。在JDK7中使用头插法,我们就需要对每个元素重新进行hash计算
14.HashMap 是线程安全的吗?
不是,要保证线程安全的话推荐使用CurrentHashMap(内有CAS锁和synchronized 关键字保证线程安全),在多线程下可能会导致环状链表,当Put触发扩容的时候,其它线程又在get,可能找不到结果。
15.HashMap 内部节点是有序的吗?
无序的,根据 hash 值随机插入,要实现有序就得使用LinkedHashMap,其维护了一个双向链表
16.TreeMap 和 HashMap 的区别
HashMap 是基于数组+链表+红黑树实现的,put 元素的时候会先计算 key 的哈希值,然后通过哈希值计算出元素在数组中的存放下标,然后将元素插入到指定的位置,如果发生哈希冲突,会使用链表来解决,如果链表长度大于 8,会转换为红黑树。
TreeMap 是基于红黑树实现的,put 元素的时候会先判断根节点是否为空,如果为空,直接插入到根节点,如果不为空,会通过 key 的比较器来判断元素应该插入到左子树还是右子树。
在没有发生哈希冲突的情况下,HashMap 的查找效率是 O(1)。适用于查找操作比较频繁的场景。
TreeMap 的查找效率是 O(logn)。并且保证了元素的顺序,因此适用于需要大量范围查找或者有序遍历的场景。