终于能用博客来写自己的知识点了,现在把之前学到的知识点全部补上去
- 字符串源码解读
- 字符串常量池
- String.Bulider和String.Buffer
- 字符串常用的方法
- 持续更新中
字符串源码解读
通过源码来学习内容是最直接了解到底层的方法,让我们先从从字符串的声明开始看,之后就会进入源码中不得不谈及的三个重要的方法

从源码中我们能得到三个信息
首先,String 类是 final 的,意味着它不能被子类继承。
其次,String 类实现了 Serializable 接口,意味着它可以序列化(序列化在网络编程中的使用十分广发,可以说在网络通信编程中传递数据都会要求数据能够被序列化)
最后,String 类实现了 Comparable 接口,意味着最好不要用‘==’来比较两个字符串是否相等,而应该用 compareTo() 方法去比较(这里提一嘴“==”与“equal”的不同,比较(这里之后会添加超链接))
还有一点很重要的是String的底层数据由char数组变成了byte数组,因为在某些编码要求之,如果使用char数组,英文字符会占用两个字节,中文字符会占用两个字节。但如果变成了byte数组,英文字符就只会占用一个字符,中文字符依旧占用两个字节,这会显著减少我们字符串对内存的占用情况,也减少了我们GC(这里之后要添加一个GC回收的链接)回收的压力
字符串的源码解读—hashcode方法
hashcode方法是什么,为什么要使用hashcode方法?
首先hash是一种计算方法,每个字符串都会有一个他自己的hash值,并且大概率不会重复,这是为了方便我们去使用哈希表(这里之后放一个连接),了解完哈希表之后就知道为什么了
我们来看源码,源码有一个很重要的计算,我们称之为31倍哈希算法,其实内容很简单,遍历字符串,对于字符串的每一位,从左到右取其ASCII码并且*其对应的阶级,最后求和,我们可以手搓一个简单的代码来模拟这个过程
String s = abcdefghikj;
int h = 0;
for(int i=0;i<s.length;i++){
h = 31*+s.char(i)
}请注意这里是怎么进行幂运算的,我第一次看的时候觉得十分的巧妙,直接进行幂运算会减慢JVM的速度

字符串的源码解读—substring方法
public String substring(int beginIndex) {
// 检查起始索引是否小于 0,如果是,则抛出 StringIndexOutOfBoundsException 异常
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
// 计算子字符串的长度
int subLen = value.length - beginIndex;
// 检查子字符串长度是否为负数,如果是,则抛出 StringIndexOutOfBoundsException 异常
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
// 如果起始索引为 0,则返回原字符串;否则,创建并返回新的字符串
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}substring 方法首先检查参数的有效性,如果参数无效,则抛出 StringIndexOutOfBoundsException 异常(这里之后会放置一个连接)。接下来,方法根据参数计算子字符串的长度。如果子字符串长度小于零,也会抛出 StringIndexOutOfBoundsException 异常。
如果 beginIndex 为 0,说明子串与原字符串相同,直接返回原字符串。否则,使用 value 数组(原字符串的字符数组)的一部分 new 一个新的 String 对象(字符串是不可变的这个思想的体现)并返回。
更多的字符串使用方法和其工具类的使用我会在别的文章中给出(这里之后要给上连接)
字符串常量池
首先我在这里给出一个拙见,1.对于在编译时将能知道的量,那么这个量就会被放进常量池中。2.使用new方法就一定会创建出新的对象(当然以上两种说法还有待更多的考证,目前来说还没出过问题)字符串也不例外。我们来看下面这个例子(同时我也会详细说说intern这个方法)
String a = new String("abc");
String b = abc;
这个地方一共创造了几个对象呢,(可能会和变量搞混,这里再提一个问题一共创建了几个变量)答案
一共有两个对象,两个变量引用,请不要搞混乱,毕竟学得越多我们就弄容易把知识弄混
对于” “直接引用的对象,JVM在编译时会自动把这部分放进常量池(如果常量池中之前没有)中,这就是编译时就能知道的量。这里是一个对象。
第二个对象则是说法二中的new,new一定会创建一个新的对象,而对于b来说,他会直接引用字符串常量池中的abc的地址,大体如下(图中我为了方便使用的是Java7时期的永久代形式,后面会提及这个是什么),变量声明在栈上,对象声明在堆中(这个地方存疑,我记得有直接声明在栈上的变量)
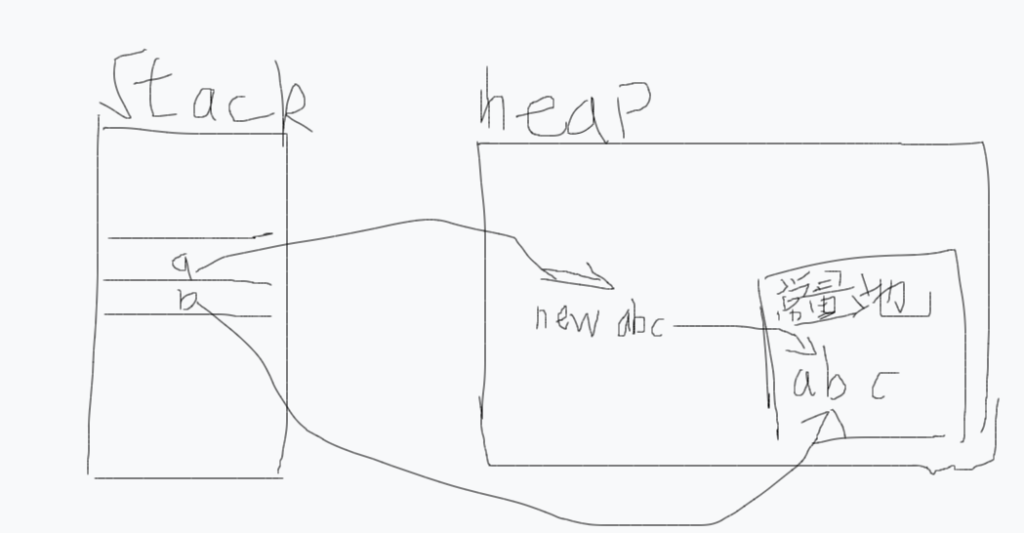
那么这样会有什么好处呢,很明显的一点就是高效,我们创建字符串给的时候是不是直接
String a = ”hello“,而且不是 String a = new String(”hello“),JVM已经帮我们省去了new这一步的操作,自然就快很多啦
那么我们再来看看下面这个例子
String a = new String("hello")
String b = intern("hello")
Stirng c = a.intern
答案
依旧两个对象,intern会返回常量池中的地址,如果这个intern需要的值被声明在了堆上,那么就会引用堆上的。intern会把这个字符串内容放到常量池中。
字符串常量池—永久代和元空间
上面我提到我是使用永久代的方法来表现字符串常量池的位置,其实它的位置是有一个历程的,现在使用的是元空间的形式,我们来一个个看。
永久代时期
出现在JAVA7之后的一段时间中,永久代是一段堆中的大小恒定的内存空间(也就是说不仅仅装的是字符串常量池),Java7之前字符常量池就放在永久代中,但不仅永久代受到堆内存的影响,字符串常量池也受到永久代的影响,所以之后我们将其移动到堆中,
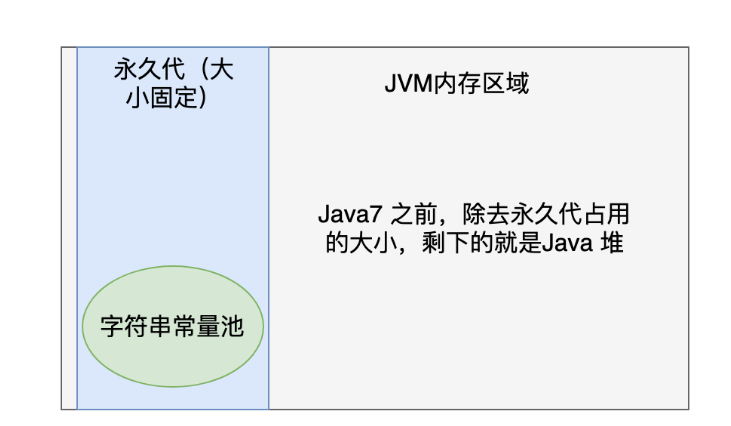
但还是会受到堆内存的影响,如果我们创建了许多的对象,就会出现OOM错误

所以我们使用元空间来存放字符串常量池,它直接部署在主机的内存上,这样就直接取决于主机内存的大小,这样就不会导致OOM,并且回收机制的声明周期也是分开计算的

String.Bulider和String.Buffer
为什么要有这两个东西呢,原因很简单,String是不可变的,每次我们对字符串对象进行操作的时候实际上都是返回一个新的字符串对象,特别是我们使用+拼接字符串对象的时候,频繁的使用+会导致不必要的对象产生,造成内存的消耗。
那么两个有什么区别,很简单,Bulider是线程安全的,因为添加了Synchronized(这里之后添加一个连接跳转过去),但也是因为如此,在单线程的使用环境下执行效率很低。Buffer没有这样的关键字,在单线程环境下执行效率高,如果遇到多线程环境就使用Thredlocal(这里添加一个跳转连接)就行
Bulider内部方法类源码解读—toStirng
toString老生常谈,用于转换字符串使用的,我们来看看这部分的源码,也是很好解读
public String toString() {
return new String(value, 0, count);
}
大体意思是有一个value的字符数组,大小默认为16(会自动扩容),将要转换的字符串从0到count转入value字符数组中,并且也能看出我前面提到的思想,对字符串的操作是返回一个新的对象
Bulider内部方法类源码解读—append
依旧先看源码
public StringBuilder append(String str) {
super.append(str);
return this;
}
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
实际上我们append调用了父类AbstractString的方法,这个方法会先判断要字符序列的空间是否够用,不够用将会进行扩容,扩容完毕之后加入要添加的字符,这个扩容方法是
private void ensureCapacityInternal(int minimumCapacity) {
// 不够用了,扩容
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
void expandCapacity(int minimumCapacity) {
// 扩容策略:新容量为旧容量的两倍加上 2
int newCapacity = value.length * 2 + 2;
// 如果新容量小于指定的最小容量,则新容量为指定的最小容量
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
// 如果新容量小于 0,则新容量为 Integer.MAX_VALUE
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
// 将字符序列的容量扩容到新容量的大小
value = Arrays.copyOf(value, newCapacity);
}ensureCapacityInternal(int minimumCapacity) 方法用于确保当前字符序列的容量至少等于指定的最小容量 minimumCapacity。如果当前容量小于指定的容量,就会为字符序列分配一个新的内部数组。新容量的计算方式如下:
- 如果指定的最小容量大于当前容量,则新容量为两倍的旧容量加上 2。为什么要加 2 呢?对于非常小的字符串(比如空的或只有一个字符的 StringBuilder),仅仅将容量加倍可能仍然不足以容纳更多的字符。在这种情况下,+ 2 提供了一个最小的增长量,确保即使对于很小的初始容量,扩容后也能至少添加一些字符而不需要立即再次扩容。
- 如果指定的最小容量小于等于当前容量,则不会进行扩容,直接返回当前对象。
在进行扩容之前,ensureCapacityInternal(int minimumCapacity) 方法会先检查当前字符序列的容量是否足够,如果不足就会调用 expandCapacity(int minimumCapacity) 方法进行扩容。expandCapacity(int minimumCapacity) 方法首先计算出新容量,然后使用 Arrays.copyOf(char[] original, int newLength) 方法(这里之后加一个连接)将原字符数组扩容到新容量的大小。这里也能看出,这个过程是有一个复制的过程
Bulider内部方法类源码解读—reverse
public AbstractStringBuilder reverse() {
int n = count - 1; // 字符序列的最后一个字符的索引
// 遍历字符串的前半部分
for (int j = (n-1) >> 1; j >= 0; j--) {
int k = n - j; // 计算相对于 j 对称的字符的索引
char cj = value[j]; // 获取当前位置的字符
char ck = value[k]; // 获取对称位置的字符
value[j] = ck; // 交换字符
value[k] = cj; // 交换字符
}
return this; // 返回反转后的字符串构建器对象
}观察源码就能发现源码巧妙的地方,其实只遍历了整个字符串的前半部分,然后每一个前半部分计算出其对应的调换位置,用两个临时遍历来存放要交换的值就可以了(我感觉用一个变量就足够了),其实反转这个地方大有学问,在算法中会经常提及(这里会有一个算法的链接)
字符串常用方法
单纯是String类的原生方法有
int length()
char charAt(int index)
int indexOf(String str)
int lastIndexOf(String str)
boolean contains(CharSequence s)
String substring(int beginIndex)
String substring(int beginIndex, int endIndex)
String concat(String str)
char[] toCharArray()
byte[] getBytes()
String toLowerCase()
String toUpperCase()
String replace(char oldChar, char newChar)
String replace(CharSequence target, CharSequence replacement)
String replaceAll(String regex, String replacement)
String replaceFirst(String regex, String replacement)
String replace(char oldChar, char newChar)
String replace(CharSequence target, CharSequence replacement)
String replaceAll(String regex, String replacement)
String replaceFirst(String regex, String replacement)
boolean equals(Object obj)
boolean equalsIgnoreCase(String anotherString)
boolean isEmpty()
boolean startsWith(String prefix)
boolean endsWith(String suffix)
String trim()
int compareTo(String anotherString)
int compareToIgnoreCase(String str)
String[] split(String regex)
boolean matches(String regex)
来自StringUtils工具类的有
StringUtils.isBlank(String str)
StringUtils.isEmpty(String str)
StringUtils.join(List list, “, “)
StringUtils.split(String str, “,”)
StringUtils.strip(String str)
StringUtils.capitalize(String str)
StringUtils.equalsIgnoreCase(String a, String b)
不需要死记,多实践使用就会熟悉了